InterDyn: Controllable Interactive Dynamics with Video Diffusion Models


We adress the task of synthesizing human-object interactions in image space. Given an input image and a motion cue (e.g., a sequence of hand masks), InterDyn generates plausible videos that realistically capture human motion and its interaction with objects in the scene. This work demonstrates how foundation models can serve as neural physics engines, generating realistic scene dynamics without the need for explicit physical simulation.
Object collision events
We start our investigation by probing the ability of SVD to generate interactive dynamics using the synthetic CLEVRER dataset. We examine whether the model can produce object movements for uncontrolled objects in the scene, given the movement of objects entering the scene. For instance, determining how an object would move if struck by another.
Compared to ground truth physics-simulated renderings, InterDyn synthesizes dynamics that are physically plausible without explicit knowledge of the objects’ mass or stiffness.
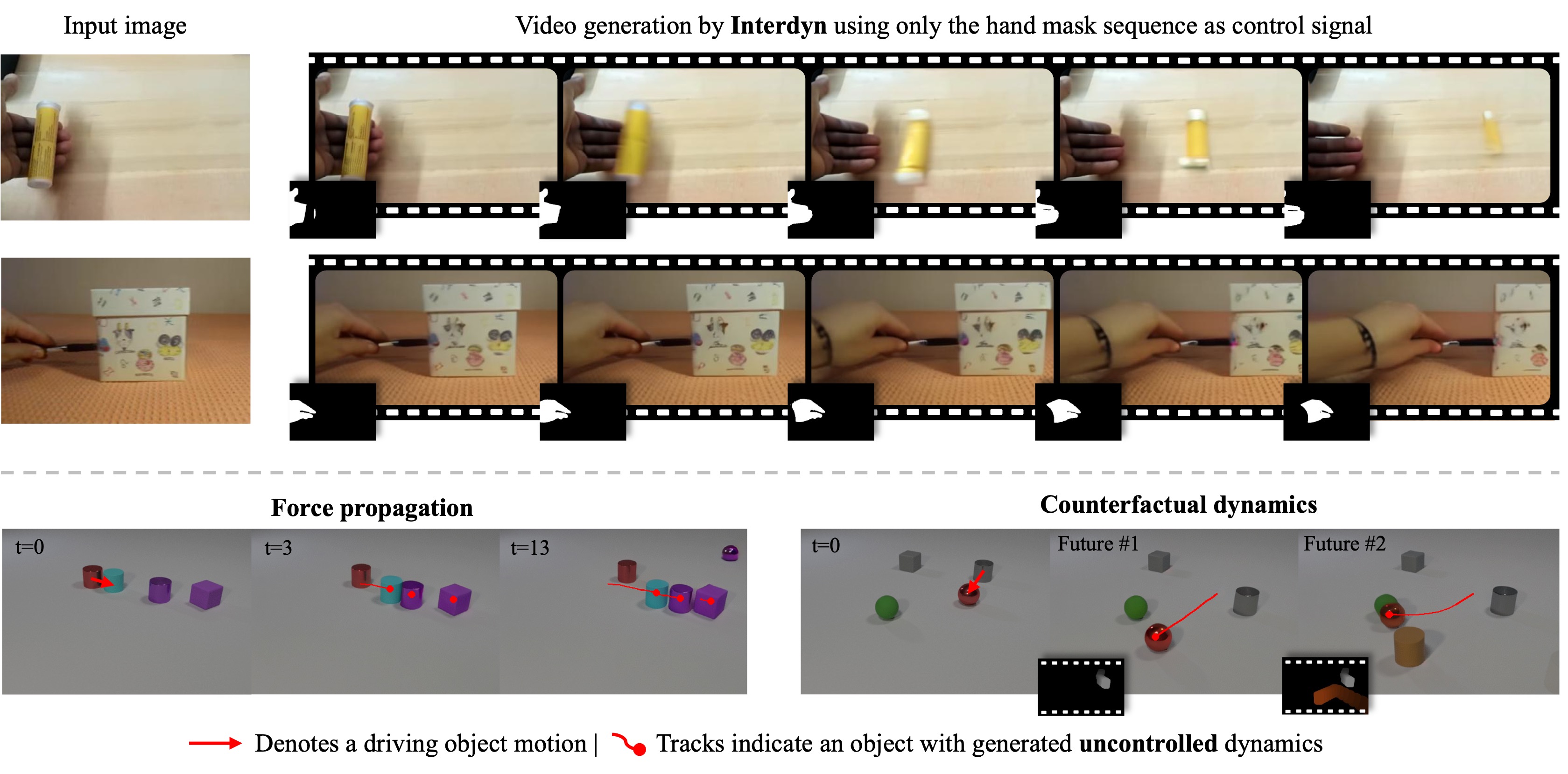
InterDyn can also generate force propagation dynamics, where uncontrolled objects interact with each other.
InterDyn can generate realistic motions under counterfactual scenarios, where different interaction configurations lead to different causal effects—much like a physics simulator.
Hand-Object Interaction
We continue by evaluating InterDyn in a more complex, real-world scenarios offered by the Something-Something-v2 dataset. Originally proposed for human action recognition and video understanding, this dataset provides 220,847 videos of humans performing basic actions with everyday objects.
Sudhakar et al. recently proposed CosHand, a controllable image-to-image model based on Stable Diffusion that infers state transitions of an object. We compare InterDyn with two CosHand variants: a frame-by-frame approach and an auto-regressive approach.
BibTeX
If you find this work helpful, please consider citing
@inproceedings{akkerman2025interdyn,
title={InterDyn: Controllable Interactive Dynamics with Video Diffusion Models},
author={Akkerman, Rick and Feng, Haiwen and Black, Michael J. and Tzionas, Dimitrios and Abrevaya, Victoria Fern{\'a}ndez},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={12467--12479},
year={2025}
}